Insights
Card Visual 1
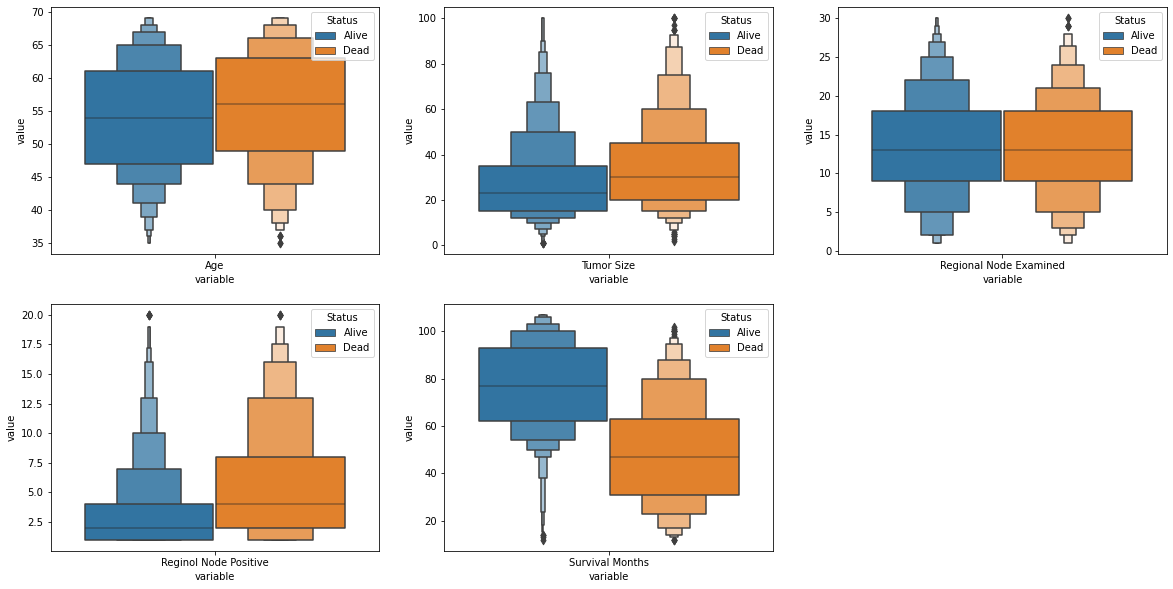
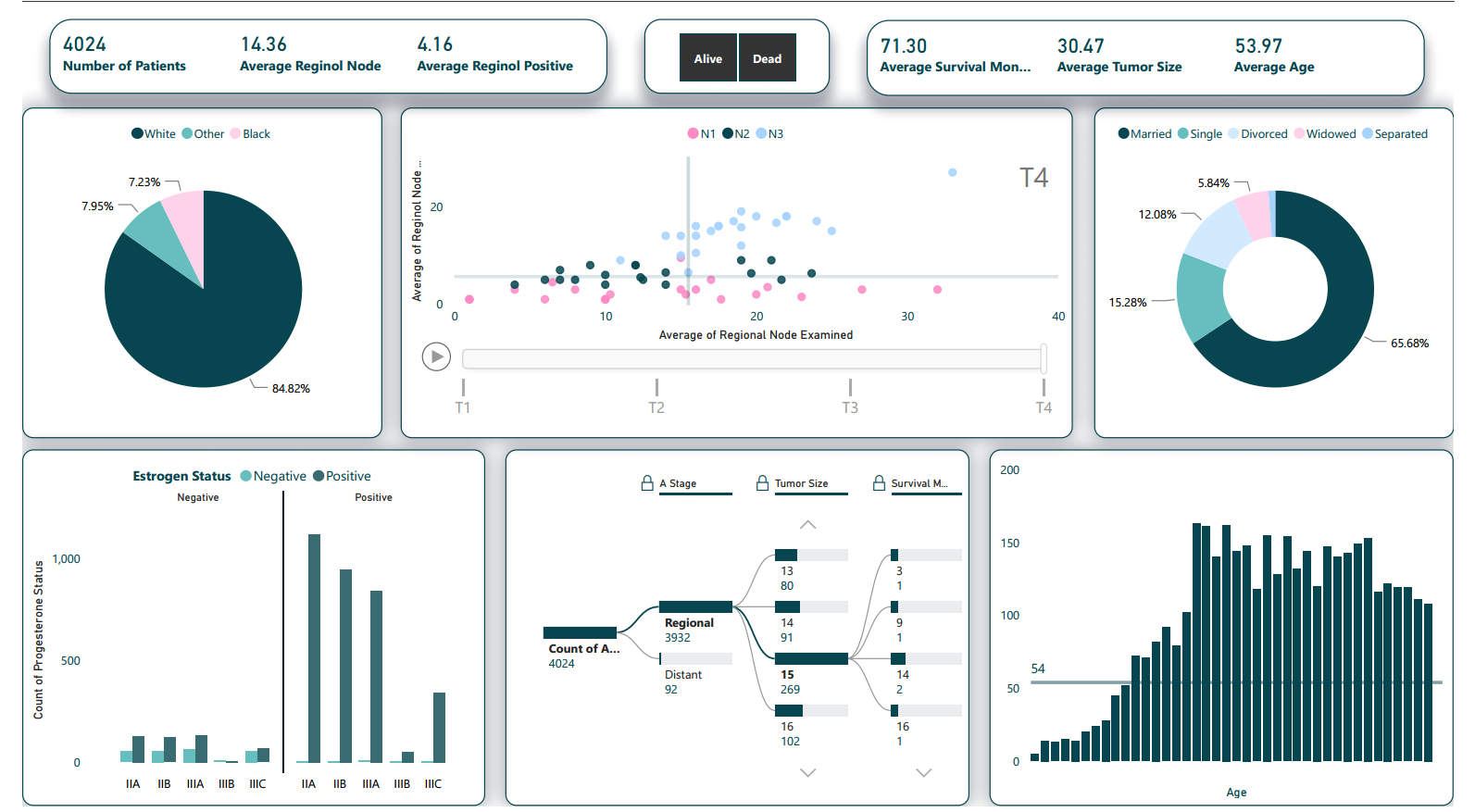
Number of Patients (4024):
The total number of cancer patients currently under care is 4024. This metric underscores the hospital's substantial role in catering to the needs of a significant patient population, highlighting the importance of efficient resource allocation and timely care delivery.Average Regional Node Value Examined (14.36):
On average, each patient has undergone examination of approximately 14.36 regional lymph nodes. This metric reflects the thoroughness of the diagnostic process, indicating that a comprehensive assessment is conducted to ensure accurate cancer staging and treatment planning.Average Regional Node Value Positive (4.16):
Among the examined regional lymph nodes, the average number of nodes found to be positive for cancer is 4.16. This insight offers a glimpse into the extent of cancer progression within the patient population and aids in understanding the disease's severity distribution.Relation between Regional Node Examination and Positivity by N Stage
Insights
N1 (Lower Positivity, Comparable Examination): Patients in N1 stage exhibit a lower average regional node positivity. However, their average node examination is quite similar to other stages, suggesting thorough diagnostic evaluation even in cases with relatively lower positivity.N2 (Moderate Positivity, Higher Examination): N2 stage patients display a moderate average regional node positivity, indicating a more significant cancer presence. Their average node examination is higher, suggesting a more meticulous evaluation to detect possible cancer spread.
N3 (Higher Positivity, Higher Examination): Patients categorized under N3 stage show the highest average regional node positivity, signifying advanced cancer. Their average node examination is also greater, highlighting the need for comprehensive scrutiny due to the heightened risk of extensive lymph node involvement.
In summary, the "Relation between Regional Node Examination and Positivity by N Stage" scatter plot showcases a pattern wherein N Stage progression aligns with increasing average regional node positivity, underscoring the significance of comprehensive node examination.
Distribution Of Patients By Marital Status
Married Patients (65.68%): The dominant category, married patients, form the largest segment. This could imply that a significant portion of the patients might have a support system in place, which can impact decision-making, emotional well-being, and care management.Single Patients (15.28%): Single patients represent a notable segment, underscoring the importance of providing holistic support and guidance for individuals who might not have immediate familial support during their cancer journey.
Divorced Patients (12.08%): The presence of divorced patients highlights the unique challenges faced by individuals who may be navigating cancer treatment without the support of a spouse, potentially impacting decisions and care plans.
Widowed Patients (5.84%): The widowed segment underscores the emotional and psychological needs of patients who have experienced loss, necessitating a compassionate and tailored approach to care.
Progestrone and Estrogen Status by 6th Stage
Negative Progestrone with Estrogen Status:This portion of the chart represents patients with a negative Progestrone status, further divided by their Estrogen status. Key observations include: Across all 6th Stage categories, the negative Progestrone status exhibits a lower count of patients. The highest count within this category is observed in the 6th Stage category with a slight elevation in positive Estrogen status. However, none of the values exceed 100.
Positive Progestrone with Estrogen Status:
On the positive Progestrone side, this portion of the chart also categorizes patients based on their Estrogen status. Notable insights include: The positive Progestrone side generally showcases higher counts across all stages, indicating a higher prevalence of positive Progestrone status. In stages IIA, IIIA, and IIB, the counts of patients with positive Estrogen status are significantly higher, exceeding 500 in each of these stages. In stages IIIB and IIIC, the count of patients with positive Estrogen status is notably lower, not surpassing 500.
Patient Composition by A Stage, Tumor Size, and Survival Months
A Stage:This component of the chart categorizes patients based on their A Stage classification. Notable observations include: The largest portion of patients is concentrated in the "Regional A" stage, indicating that a significant majority of patients fall within this category. This dominance suggests that a considerable number of patients are diagnosed at an earlier stage, which can impact treatment options and overall prognosis positively.
Tumor Size:
The second layer of the chart further breaks down the patients based on their tumor size. Noteworthy insights include: Among patients in the "Regional A" stage, a substantial portion exhibits a tumor size of "15 upwards". This suggests that even within the earlier stage, a notable number of patients may have larger tumors, which could influence treatment approaches and prognosis.
Survival Months:
The third layer provides insights into patient survival based on the number of months. Key observations are as follows: Among patients in the "Regional A" stage and with a tumor size of "15 upwards", a significant portion has a survival duration of "14 upwards" months. This insight indicates that a substantial number of patients in this specific subgroup experience longer survival periods, reflecting the potential effectiveness of treatments and interventions.
Distribution of Patient Age
Skewed to the Left with Concentration in the Mid-Section:The histogram exhibits a left-skewed distribution, with a concentration of patients in the mid-section of the age ranges. Most patients are found within the mid-range of ages, indicating that a significant proportion of the patient population falls between these ages. The skewness suggests that while there are some patients at younger and older ages, the majority of patients cluster within a specific age range.
Age Range and Statistics:
The age ranges captured in the histogram span from 30 to 69 years, reflecting the diversity of ages among the patients. The histogram characteristics, including the mean age of 53 and the median age of 59, signify the central tendency of the age distribution. The mean and median ages provide a quantitative summary of the data, reinforcing the observation of the concentration of patients around the mid-section of the histogram.
Dashboard General Summary, Conclusion and Recommendations
General Summary:
The development of the Cancer Monitoring Dashboard at [Hospital Name] has revolutionized the way cancer patient care is managed and prioritized. The dashboard offers a comprehensive and intuitive visual interface that empowers healthcare professionals with real-time insights, enabling them to make informed decisions for efficient resource allocation, patient appointment scheduling, and personalized treatment strategies.Conclusion:
The Cancer Monitoring Dashboard provides a holistic view of critical patient data, including cancer stage, node examination, positivity, marital status, and age distribution. This enables timely identification of high-priority patients, effective allocation of medical resources, and tailored care plans. The integration of Power BI has streamlined data visualization, enabling stakeholders to glean actionable insights effortlessly.Recommendations:
Continuously update and maintain the dashboard to reflect the most recent patient data and trends.Explore the possibility of incorporating predictive analytics to forecast patient needs and optimize resource allocation further.
Gather feedback from healthcare professionals and stakeholders to refine and enhance the dashboard's usability and functionality.